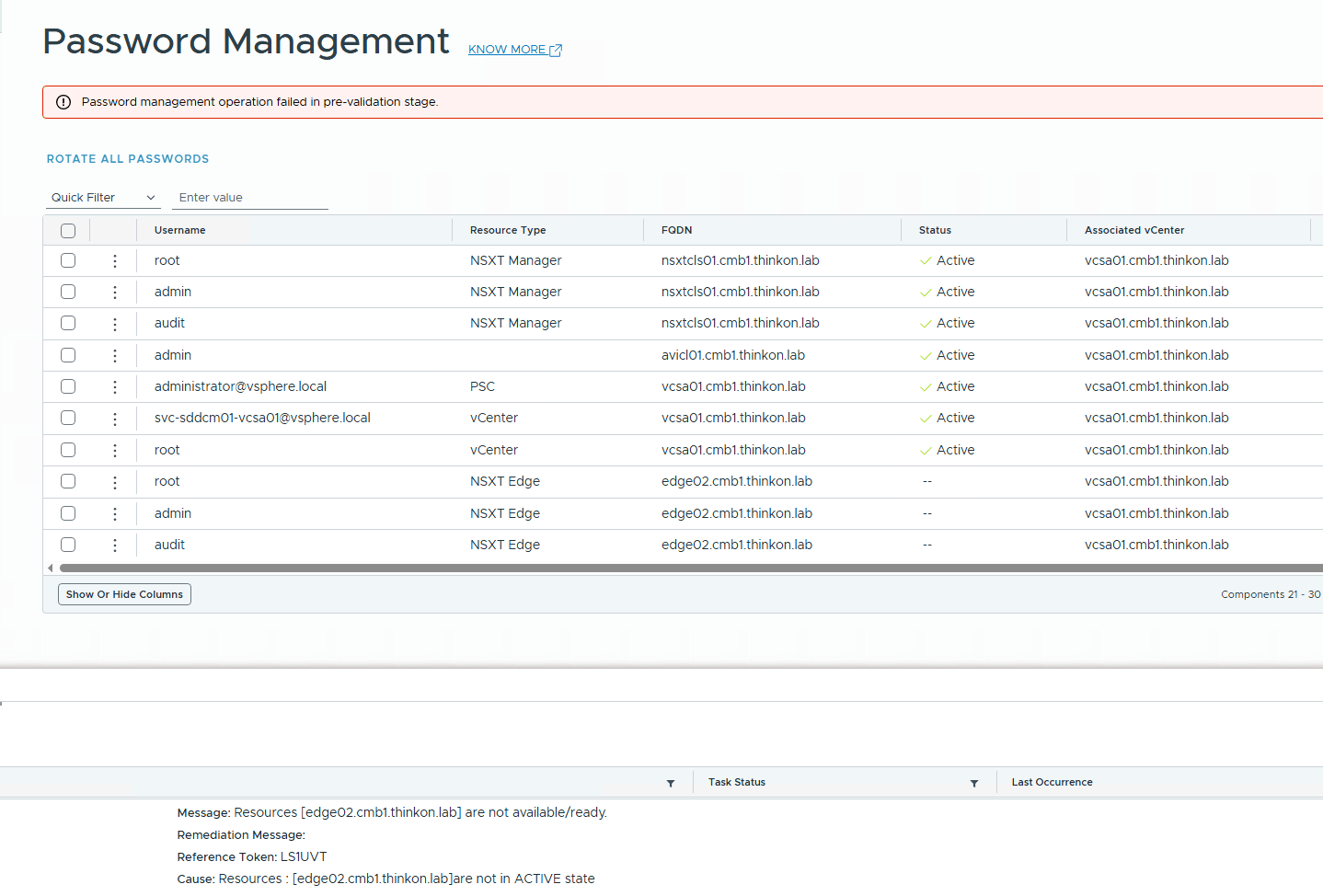
Welcome to part 14 of the VCF-9.1 home lab series. The previous post in this series discussed the architecture and deployment of a VNA cluster for distributed connectivity. This post will discuss implementing the distributed transit gateway for VPC connectivity.
If you are not following along, I encourage you to read the earlier parts of this series from the links below:
3: VCF 9.1 Pre-Deployment Planning
4: Setting up VCF 9.1 Offline Depot
5: VCF 9.1 Deploy Management Domain
6: Configure Management Domain Network Connectivity
8: Enable Avi on Workload Domain
9: Deploy Supervisor in Workload Domain
11: VCFA Provider Management Configuration
12: Deploy VCF Operations for Logs
13: VNA Cluster for Distributed Connectivity
Within a VPC, routing between subnets is handled by a VPC Gateway, which behaves like a distributed tier-1.… Read the rest