

Before an upgrade bundle can be applied to a workload domain (Mgmt or VI), the SDDC manager trigger a precheck on the domain to identify and alert if there is an underlying issue, so that the issue can be remediated before applying the upgrade bundle. In lab environments, one of the common precheck failures is regarding the vSAN HCL compatibility.
In lab environments, you might be running VCF on unsupported hardware that is not present in the vSAN HCL
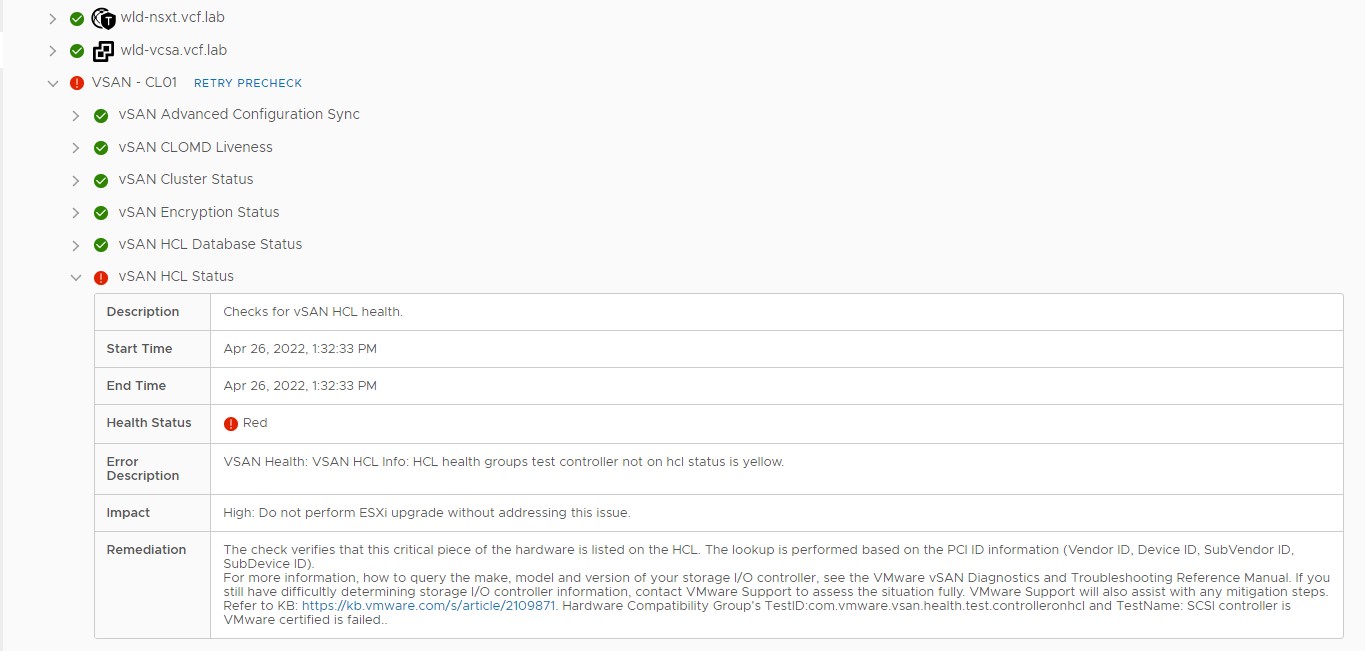
During upgrade precheck on the workload domain, you will see the vSAN HCL status as Red, and SDDC Manager won’t let you upgrade the domain until the issue is fixed.
You can force SDDC Manager to ignore the vSAN precheck by adding the following lines in the applications-prod.properties file and modifying the below entries. The file is located in the directory “/opt/vmware/vcf/lcm/lcm-app/conf”
Change the vsan health check related data from true to false. … Read More